Never forget anything
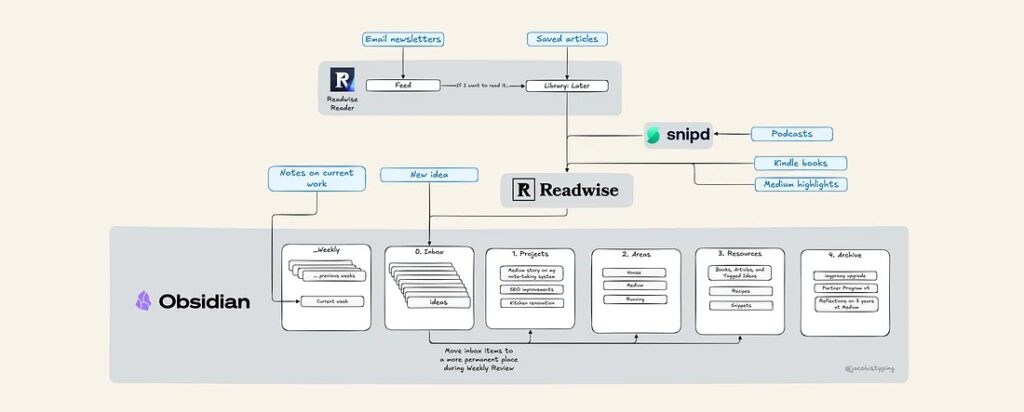
The software engineer’s over-engineered knowledge management system
I take lots of notes. And I forget lots of things.I’ve written thousands of notes. Sometimes they’re as benign as a quick shopping list for a trip to the market. Or I’ll jot something down that someone said in a meeting. And I have plenty of book outlines that hold my mental model of a concept I’ve studied.But I’ve lost more ideas than I’ve remembered. I’ve thrown away physical notebooks and deleted digital ones when they became too difficult to search through. My personal knowledge “system” was more like a junk drawer than a library.Press enter or click to view image in full size(screencaps from Brooklyn Nine-Nine)Over the last few years, I put together a system that finally started to work for me. And I stopped forgetting things.Call it a “Second Brain” or a “Personal Knowledge Management” system. Whatever. It works really well for me. I just call it “my notes.”My non-negotiables for a working knowledge libraryI have 3 requirements that I won’t compromise on for a working system.Create an account to read the full story.The author made this story available to Medium members only.If you’re new to Medium, create a new account to read this story on us.Continue in appOr, continue in mobile webSig
RAG Without Embeddings? Here’s how OpenAI is doing this…with Code
Level Up Coding·Follow publicationMember-only storyRAG Without Embeddings? Here’s how OpenAI is doing this…with CodeGaurav ShrivastavGaurav ShrivastavFollow9 min read·Jun 11, 2025ListenShareHow OpenAI Could Change the Way We Retrieve Information — Without Embeddings or Vector DatabasesImage by OpenAIIf you’re building with large language models (LLMs), you’ve probably wrestled with Retrieval Augmented Generation (RAG). It’s brilliant for grounding LLMs with external data, but the “R” part — Retrieval — can be complex.Non Members can read HereSupport me here: https://coff.ee/gaurav21s
I know I’ve spent hours pondering chunk sizes, overlap strategies, and which embedding model to pick. And managing vector databases? That’s a whole infrastructure challenge.So, when I stumbled upon OpenAI’s recent work in their Cookbook on a different RAG approach — one that promises to bypass traditional embeddings — my developer brain did a little flip. Could we really get great retrieval results without the vector database dance? This idea felt genuinely pattern-breaking.The secret sauce seems to be leveraging the massive context windows of newer models like GPT-5 and Gemini Flash. Models that can process a million tokens at once enable entirely new workflows. But is context window size the only factor at play?Beyond the Standard RAG Pipeline
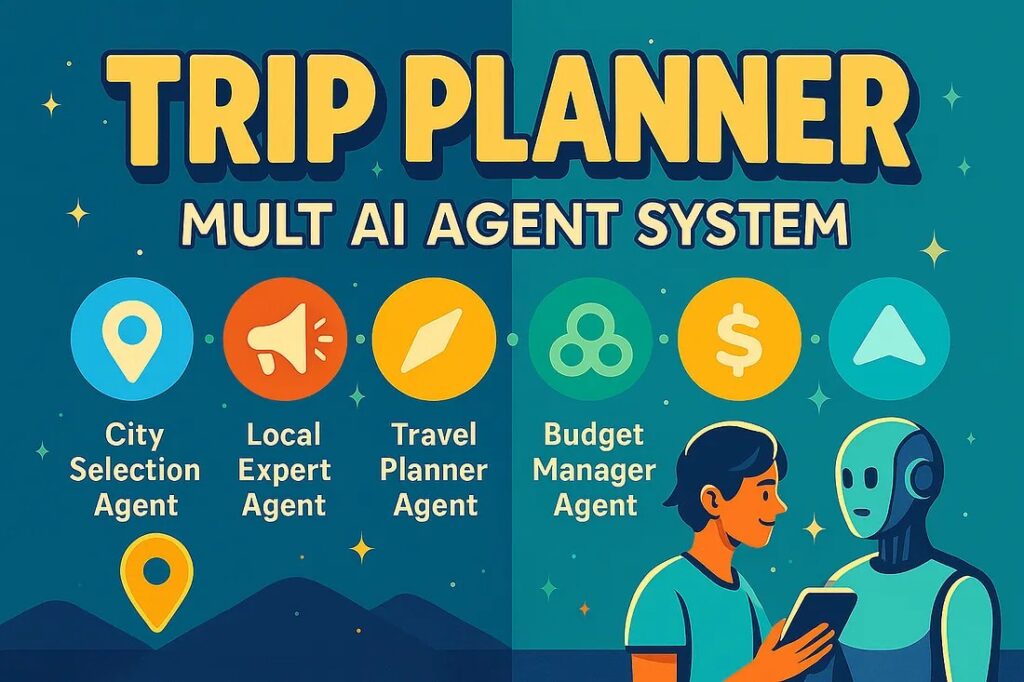
Designing Multi AI Agent Architecture to Plan My Perfect Trip, And You Can Too
End to End Multi Agent Project to Create Perfect Travel Plans Within Any Budget
Support me here: https://coff.ee/gaurav21s
Non members can read Here
Introduction
Ever found yourself drowning in a sea of browser tabs while trying to plan a vacation? One tab for flights, three for hotels, ten for “best things to do in Goa, India,” and another for figuring out if you can even afford it all. It’s a mess. I got tired of that whole dance, especially the part where a “perfect” itinerary falls apart because it completely ignores the budget.
So, I got to thinking. What if I could build my own team of AI travel experts? Not one single AI trying to do everything, but a crew of specialized agents, each a pro in their own area, working together to build a complete, realistic trip plan.
That’s what this project is all about. It’s a dive into how you can get multiple AI agents, powered by models like GPT-4, to collaborate on a complex task. I used a framework called CrewAI to manage the team, and the results were pretty eye-opening.
Try the TripPlannerAI here: TripPlanAI