Sarvam AI is a Bengaluru-based startup focused on building a sovereign AI ecosystem for India, specializing in large language models (LLMs) and voice interfaces tailored for Indian languages and culture.
Sarvam AI
Sarvam AI focuses on the development and deployment of generative AI technology in the artificial intelligence industry. The company’s main offerings include the creation of large language models tailored to India’s diverse linguistic culture and an enterprise-grade platform for the development and evaluation of generative AI applications. Sarvam AI primarily serves the artificial intelligence industry. It was founded in 2023 and is based in Bengaluru, India.
Sovereign by design
Build, deploy, and run AI with full control, developed and operated entirely in India
State of the art Models
Industry-leading models built for India’s languages, culture, and context
Human at the core
Forward deployed engineers work alongside your teams to deliver production-ready agents
Population-scaleApplications
Building products India can use. Conversational agents fluent in India’s languages. Platforms that run enterprise workflows from start to finish.
State-of-the-artModels
State-of-the-art models trained on sovereign data, delivering strong performance across Indian languages.
Infrastructuretoservemodelsefficiently
A token factory built to handle complexity of model serving so teams can focus on building products, not managing infrastructure.

Sarvam Cloud
Fully managed, automatic scaling, fastest time-to-value

Private Cloud (VPC)
Your security perimeter, our management

On-Premises
Full control, air-gapped for regulated industries

“Voice-driven AI is reshaping customer engagement, moving beyond transactional touchpoints to more meaningful, personalized conversations at scale. With customers increasingly expecting immediacy and more contextual interactions, voice-led AI is emerging as a natural way to engage them across the loan journey, anchored by a strong human-in-the-loop framework that ensures accuracy, empathy, and trust.
Our partnership with Sarvam has enabled us to scale highly personalized, product and segment-specific conversations across the customer lifecycle.
By embedding multilingual interactions across our consumer loan products, we are reaching more customers with greater relevance, breaking access barriers, and deepening engagement in a cost-effective manner.”
Tata Capital’s Background
Tata Capital Limited, the flagship financial services arm of the Tata Group, has emerged as one of India’s leading and most diversified financial institutions. With expanding portfolio spanning retail, corporate, and digital-first financial products, Tata Capital serves millions of customers across urban, semi-urban, and rural India.
As the organization scales its footprint and customer base, the need to deliver consistent, personalized, and accessible engagement at scale becomes imperative. To support this requirement, Tata Capital began embedding AI-led capabilities across its product and service ecosystem, leveraging multilingual conversational AI and voice-led automation across the loan value chain. With the objective of hyper-personalisation & superior customer experiences across geographies, without compromising efficiency or human oversight.
Business Context
Tata Capital’s expansion across customer segments and geographies amplified the need to support higher volumes, regional diversity, and evolving customer expectations.
The focus shifted to combining scale with contextual relevance using AI-led interactions to expand reach and accessibility, while ensuring conversations remained empathetic and seamlessly connected to human agents where needed.
Opportunities to Scale Through Collaboration
The priority was to establish a scalable, future-ready, multilingual engagement framework that could scale quickly, work reliably across Indian languages, and deliver natural, human-like conversations while seamlessly handle high-volume customer interactions.
The organisation focused on building an AI-powered engagement layer that could:
- Enable high-volume customer engagement without linear increases in cost or effort
- Support engagement volumes aligned to peak and seasonal demand
- Ensure consistent, auditable interactions across large engagement operations
- Engage customers through regional and mixed-language conversations
- Augment human agents’ efficiency
Implementation Framework
To power this transformation, Tata Capital deployed Samvaad, Sarvam AI’s enterprise-grade voice AI platform purpose-built for the Indian market.
Samvaad enables automated, conversational customer interactions in English and 10 Indian languages, allowing Tata Capital to engage customers in the language they are most comfortable with. The voice AI understands intent, handles mixed-language speech, and responds with appropriate tone and empathy, creating interactions that feel natural and human.
Built-in workflow controls and safeguards ensure conversations remain consistent and reliable. Today, a significant share of Tata Capital’s calling is handled through voice AI, with nuanced or judgment-intensive interactions seamlessly transitioned to human agents.
The Impact
- Scalability: Ability to run customer calling at very high scale without proportional increases in cost.
- Consistency: More consistent customer interactions with better coverage
- Expanded reach: Improved reach across geographies and language segments
- Higher human productivity: Human agents focussed on interactions requiring judgment
- Superior customer experience: Faster response times, language comfort, and consistent service

We recently released Sarvam Vision – a state-of-the-art 3B vision-language model for document intelligence in English and 22 Indian languages. The model achieves best-in-class scores on global benchmarks like olmOCR-Bench and OmniDocBench for English; and obtains leading accuracy on the Sarvam Indic OCR Bench for Indian languages better than frontier models such as Gemini 3 Pro, Opus 4.5, and GPT-5.2.
Today we release Akshar – a workbench tailored to solve last-mile problems in knowledge extraction. Akshar functions as the intelligence layer atop the Sarvam Vision model moving beyond passive text extraction to active reasoning. The platform equips agents with critical information – visual grounding, semantic layout details, block-level extractions – to enable automated proofreading and error corrections.
The Limits of Existing Solutions for Document Digitization
Legacy OCR Stack
Classical OCR engines – ranging from open-source staples like Tesseract and EasyOCR to enterprise APIs like Google Cloud Vision – face significant architectural constraints when processing complex, unstructured documents. These systems typically rely on a bottom-up approach, identifying characters and words in isolation without understanding the semantic or spatial context of the page. This limitation manifests as a failure in layout analysis, where multi-column contents are read linearly across the page, resulting in discontinuous text.
Furthermore, these models struggle profoundly with Indic scripts, frequently misinterpreting complex conjuncts and diacritics (matras), or failing to distinguish between body text and marginalia. Such lack of semantic understanding and context of a page renders the output unusable for downstream use cases which require full accuracy.
Multimodal Large Language Models
While modern VLMs have made major strides in document understanding, they are no silver bullet. Frontier models continue to yield low-accuracy outputs as complexity of a document increases (e.g., historical newspapers in Indian languages, publications with embedded charts, among others). This class of models have solved problems such as reading order prediction, key-value extraction, and multimodal understanding. However, they introduced additional gaps – such as probabilistic outputs, lack of auditability, and required manual tuning of prompts leading to factual inconsistencies.
What remains unsolved?
Despite all recent progress, several last-mile complexities persist: (a) zero-shot parsing of complex layouts without training; (b) capturing semantic relationships between elements; (c) visual grounding; (d) automated error localization and correction with human-in-the-loop at scale.
Sarvam Vision x Akshar: A Knowledge Extraction Workbench
Built upon Sarvam Vision’s capabilities, Akshar takes a more fundamental approach to document processing. Let’s take the case of digitizing historical documents dating back to the 1800s. The 19th-century Gujarati or Tamil manuscripts, archaic fonts and complex conjuncts (matras) often are hallucinated modern spellings at baseline. A raw API output requires a linguist to compare the text against the image line-by-line – a prohibitively slow process. Akshar solves this by coupling the VLM with an agents loop. The workbench can identify script uncertainties allowing experts to validate hundreds of pages in the time it typically takes to transcribe one.
Visual grounding
Pinpoint exact coordinates of text and elements in documents.
Layout understanding
Build a comprehensive representation of each page by understanding the semantic structure of the document.
Source Document
Input

Enrich visual components with text
Caption charts, images, and other visual elements
Source Document
Input
The project for acetic acid from methanol continues to be the news more recently after the Central Molasses Board eeting. The status of acetic acid in India was reviewed in e CHEMICAL WEEKLY (Jan. 3, 1989) and the relevance f methanol-based acetic acid referred to in these columns. fter an initial flurry of capacity approvals two years back e question was finally the approval of technology import om British Petroleum, the party who owns it, by GNFC, e party chosen by the licensor for imparting the technol- gy as a sole licencee. The proposals reported before Gov- ment of India for import of technology at over Rs. 8 crores n foreign exchange plus about Rs. 25 crores of equipment nd catalysts for a 40,000 TPA plant which may need an over- ll investment of Rs. 90 crores. This foreign exchange cost s enormous when ethyl alcohol technology needs nil. Enrich visual components with text
Caption charts, images, and other visual elements
Source Document
Input

Click a block to scroll to its text
Akshar
Sarvam
Extracted blocks · 20 detected
1. Header
fil 18, 1989
2. Header
CHEMICAL WEEKLY
3. Page No.
35
4. Headline
CHEMARENA
5. Headline
.L. VENKITESWARAN
6. Headline
Methanol-based acetic acid
7. Paragraph
The project for acetic acid from methanol continues to be the news more recently after the Central Molasses Board eeting. The status of acetic acid in India was reviewed in e CHEMICAL WEEKLY (Jan. 3, 1989) and the relevance f methanol-based acetic acid referred to in these columns. fter an initial flurry of capacity approvals two years back e question was finally the approval of technology import om British Petroleum, the party who owns it, by GNFC, e party chosen by the licensor for imparting the technol- gy as a sole licencee. The proposals reported before Gov- nment of India for import of technology at over Rs. 8 crores n foreign exchange plus about Rs. 25 crores of equipment nd catalysts for a 40,000 TPA plant which may need an over- ll investment of Rs. 90 crores. This foreign exchange cost s enormous when ethyl alcohol technology needs nil.
8. Paragraph
It is now reported that GNFC is planning to export 50% f production to their collaborator and argue that the quan- ty of 18,000 tonnes of acetic acid (at 90% capacity utili-
9. Paragraph
sation) only will hit the Indian market and therefore will have hardly any repercussion on the production from ethyl alco- hol or on molasses utilisation. Earlier there was a report that GNFC was planning doubling of capacity with 50% exports in which case 36,000 tonnes will be for Indian market. What- ever be the quantity for Indian market it is more important to see the price at which it would be sold. Earlier estimates of costs was over Rs. 11.50 per kg. on 40,000 tonnes pro- duction. If half were exported at a price of even Rs. 8 per kg, the Indian price will go up to Rs. 15.00 per kg. — far higher than the costs from ethyl alcohol. The attempts to jus- tify the project only lead to more questions on viability and the necessity for such production in the Indian context.
10. Paragraph
There is an urgent need for clearance of more projects for acetic acid from ethyl alcohol on a priority basis and finan- cial institutions would do well to reexamine their old assess- ment of GNFC’s project and decide on financial clearance of other applications pending with them.
11. Section Title
Fluoroaromatics
12. Paragraph
Fluoroaromatics particularly derivatives of trifluoromethyl enzenene have been the base for some useful pharmaceuti- als and pesticides. More recently the fluoroquinolones which ave excellent antibiotic properties have been introduced into he market, particularly norfloxacin. Now there is a build up n fluoroaromatics to meet the increasing demands. Mallin- croft Chemicals and DuPont have been the producers in USA nd are said to be doubling their capacities. ICI in UK is also a major producer with Hoechst and Rhone Poulenc in Europe. One estimate is that the world demand is about 4,000 tonnes nd expected to grow at a high rate.
13. Paragraph
The chlorofluoromethanes or CFC’s have had a notorious reputation in promoting ozone destruction in the stratosphere and indirectly promoting ultra violet radiation penetration and warming up of atmosphere which could have disastrous con- sequences. Fluoroplastics Teflon for example, have been very important but CFC’s and Teflon are based on simple ali- phatic molecules while the bioactive compounds are aro- matic or other ring compounds with fluorine as a substituent in the form of trifluoromethyl radical. There is a fluoroaro- matic resin however — PEEK-based on diflurobenzophenone. Some of the fluoropesticides are of an earlier era and most
14. Paragraph
are active herbicides. A few are still used in large volumes particularly, trifluoranil. The important products of this group of herbicides are indicated below:
15. Paragraph
Trifluoranil (Treflan)
16. Image
The image displays the skeletal chemical structure of a substituted benzene ring. The central hexagon represents the benzene ring, which is substituted at three positions. At the top position, a nitro group (NO₂) is attached. At the bottom position, another nitro group (NO₂) is attached. On the left side of the ring, a carbon atom is bonded to a trifluoromethyl group (F₃C). On the right side, a nitrogen atom is bonded to a group represented as N(C₃H₇)₂, indicating a nitrogen atom attached to a propyl group (C₃H₇). The structure is a symmetric derivative of 1,3-dinitrobenzene.
17. Paragraph
Benfluoranil
18. Image
The image displays a chemical structure diagram of a substituted benzene ring, specifically a nitroso-derivative. The central feature is a benzene ring (hexagon with a circle in the center). Attached to the ring are four substituents: a nitro group (NO₂) at the top position, a trifluoromethyl group (F₃C) at the left position, a nitrogen atom (N) at the bottom position, and a branched alkyl group on the right. This right-side group is a secondary amine, branching into two alkyl chains: an ethyl group (C₂H₅) and a butyl group (C₄H₉(n)). The structure represents a complex organic molecule, likely a precursor or intermediate in organic synthesis.
19. Paragraph
Norfluorazon
20. Image
The image displays a skeletal chemical structure diagram rather than a data chart with axes. The central core is a six-membered ring containing two Nitrogen (N) atoms and four Carbon (C) atoms. The ring is substituted as follows: a phenyl group (benzene ring) is attached to one Nitrogen atom; a carbon-carbon double bond (N=CH) connects the second Nitrogen to a carbon atom; and the remaining carbon atoms are substituted with a methyl group (-NHCH3) and a chlorine atom (Cl). Additionally, a trifluoromethyl group (F3C) is attached to one of the outer Carbon atoms. The structure represents a chlorinated, fluorinated heterocyclic compound, specifically a 1-phenyl-2-(trifluoromethyl)-4-chloropyridazine derivative.
Agent Orchestration: Plan → Reason → Act
The best document intelligence models work well on the majority of documents – achieving up to 90-95% accuracy. In domains such as healthcare, finance, government, among others, 100% is critical to aid important decision-making. Such real-world complexities can break even the most sophisticated systems.
Akshar represents a paradigm shift – from passive extraction to that of semantic understanding and contextual reasoning. By harnessing multimodal LLMs, the platform functions as a cohesive intelligence layer that reads, interprets, and executes complex flows.
How Agents Work
- Baseline Extraction: Documents are processed through Sarvam Vision’s harness modules and VLM for extractions. Agents identify, fix common errors.
- Agent Capabilities:
- Digitization: At upload time, any user-provided instructions for a document are executed autonomously across each page.
- Proofreading: Human-in-the-loop is now easier. Using the chat interface, interact with the agent to fix issues across pages or in select blocks.
- Actions and Memory: Agent performs tasks and updates memory for future recall.
All agent actions are proposed as reviewable suggestions for users to accept or reject, putting human trust and auditability front and center.
Industry Extensions
Akshar’s capabilities extend across various document types and domains:HealthcareFinancial ServicesEducationInsuranceLegalHealth CheckupBlood TestGeneral PrescriptionDental Prescription
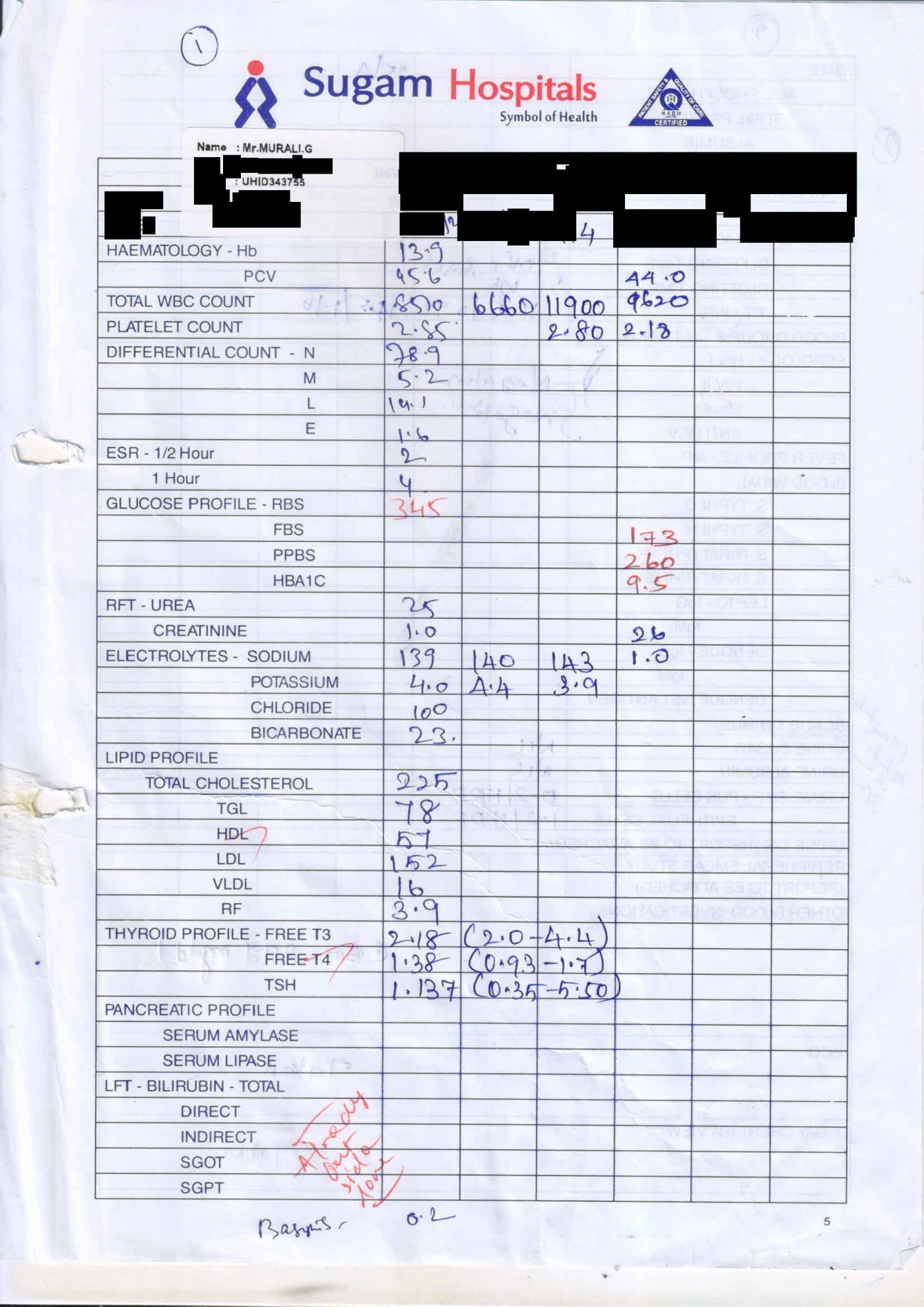
Extracted blocks · 9 detected
1. Header
This image contains no text. It is a graphic icon depicting two blue legs with red heads, likely representing people or pedestrians crossing at an intersection (a zebra crossing).
2. Section Title
Sugam Hospitals
3. Paragraph
Symbol of Health
4. Header
PATIENT SAFETY & QUALITY OF CARE NABH CERTIFIED
5. Paragraph
Name : Mr.MURALI.G
6. Table
| HAEMATOLOGY – Hb | 13.9 | |||
| PCV | 45.6 | 44.0 | ||
| TOTAL WBC COUNT | 8570 | 6660 | 11900 | 9620 |
| PLATELET COUNT | 2.85 | 2.80 | 2.18 | |
| DIFFERENTIAL COUNT – N | 78.9 | |||
| M | 5.2 | |||
| L | 14.1 | |||
| E | 1.6 | |||
| ESR – 1/2 Hour | 2 | |||
| 1 Hour | 4 | |||
| GLUCOSE PROFILE – RBS | 345 | |||
| FBS | 173 | |||
| PPBS | 260 | |||
| HBA1C | 9.5 | |||
| RFT – UREA | 25 | |||
| CREATININE | 1.0 | 26 | ||
| ELECTROLYTES – SODIUM | 139 | 140 | 143 | 1.0 |
| POTASSIUM | 4.0 | A.4 | 3.9 | |
| CHLORIDE | 100 | |||
| BICARBONATE | 23. | |||
| LIPID PROFILE | ||||
| TOTAL CHOLESTEROL | 225 | |||
| TGL | 78 | |||
| HDL | 57 | |||
| LDL | 152 | |||
| VLDL | 16 | |||
| RF | 3.9 | |||
| THYROID PROFILE – FREE T3 | 2.18 | (2.0-4.4) | ||
| FREE T4 | 1.38 | (0.93-1.7) | ||
| TSH | 1.137 | (0.35-5.50) | ||
| PANCREATIC PROFILE | ||||
| SERUM AMYLASE | ||||
| SERUM LIPASE | ||||
| LFT – BILIRUBIN – TOTAL | ||||
| DIRECT | ||||
| INDIRECT | ||||
| SGOT | ||||
7. Footer
Basysr
8. Page No.
੨
9. Page No.
5
Conclusion
By vertically integrating Sarvam Vision, Akshar aims to minimize friction between model capabilities and real-world applications. It harnesses isolated OCR problems with a comprehensive intelligence layer which orchestrates complex tasks. This approach addresses the reliability deficit inherent in modern AI systems due to their probabilistic nature, allowing us to unlock value trapped in unstructured documents.
Try it!
Akshar is built for real-world document workflows—and we’re just getting started. This is your chance to try it with documents of any kind, explore a wide range of use-cases, and traverse the last mile of accuracy. Every user gets free credits to upload documents, try Agent Mode, and experience Akshar’s capabilities end-to-end.
If you’re an individual or organization interested in using Akshar in production, we encourage you to join our waitlist from within the platform.
Extract Table
Airport arrivals board in Kannada
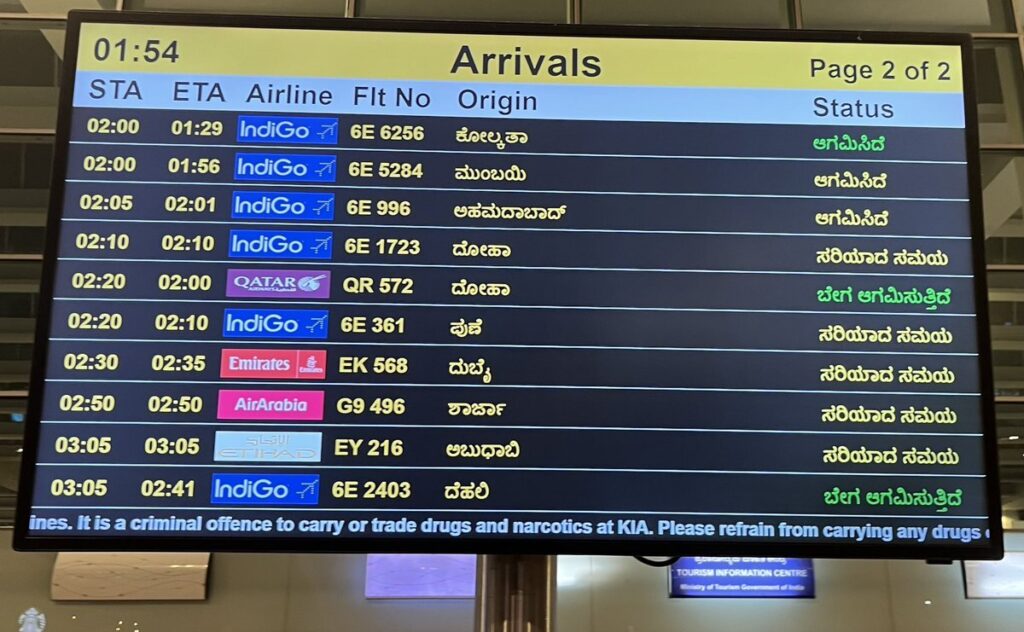
It is a criminal offence to carry or trade drugs and narcotics at KIA.
Image Caption
Railway station scene in Hindi

Read Text
Gujarati notice board

Start building!
Speech to Text
Accurate Speech Recognition
Text to Speech
Try our Speech Models
Vision
Analyze images with AI-powered vision
Voices That Feel Real
Realistic. Nuanced. Expressive.
![]()
Energetic Voice for Helpdesk
Male – Shubh
![]()
Engaging Voice for Storytelling
Male – Aditya
![]()
Deep Voice for Edtech & Media
Female – Ishita
Multi-Speaker Conversation
We have some websites, so we created an account on those websites, and normally, we get around a hundred. But we don’t get a result.
That means YouTube algorithms and Instagram have not yet fully evolved, that is also a problem because after AI came, everyone is saying that now that differentiator has not come.
An image produced by AI or human produced by human, that differentiation, we are still in the basic stage, but as time goes by, everything mixes up, and we don’t know what is true and what is false, truth and lies.
Perfect.
That’s exactly the problem, that’s it.
So now, how? You can differentiate between voices because now the voice is just the beginning.