The Full MLOps Blueprint: Data and Pipeline Engineering—Part A
Recap
Before we dive into Part 5 of this MLOps and LLMOps crash course, let’s quickly recap what we covered in the previous part.
In Part 4, we extended our discussion on reproducibility and versioning into a hands-on exploration with Weights & Biases (W&B).

We began with an introduction to W&B, its core philosophy, and how it compares side-by-side with MLflow.
The key takeaway was clear: MLflow vs W&B isn’t about which is better, it’s about choosing the right tool for your use case.

From there, we went hands-on. We explored experiment tracking and versioning with W&B through two demos:
- Predictive modeling with scikit-learn, where we:
- logged metrics
- tracked experiments
- managed artifacts
- registered models
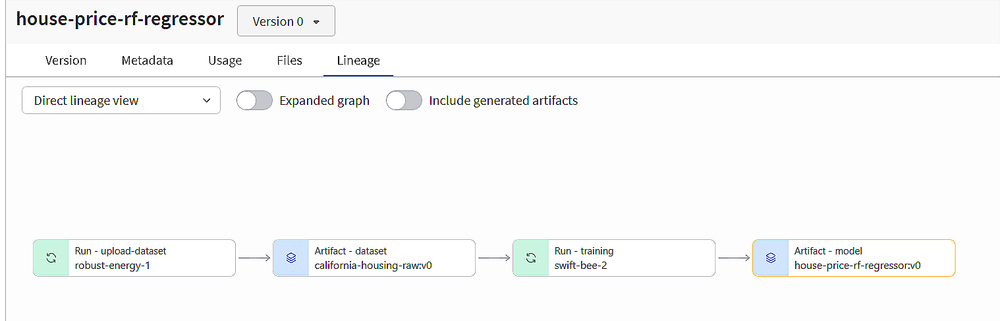
- Time series sales forecasting with PyTorch, where we learned about:
- building multi-step pipelines
-
- W&B’s deep learning integration
- logging artifacts
- checkpointing models
If you haven’t checked out Part 4 yet, we strongly recommend going through it first, since it sets the foundations and flow for what’s about to come.
In this chapter, and over the next few, we’ll explore the core concepts of data and pipeline engineering, viewed from a systems perspective. This stage forms the structural backbone that supports the implementation of all subsequent stages in the MLOps lifecycle.
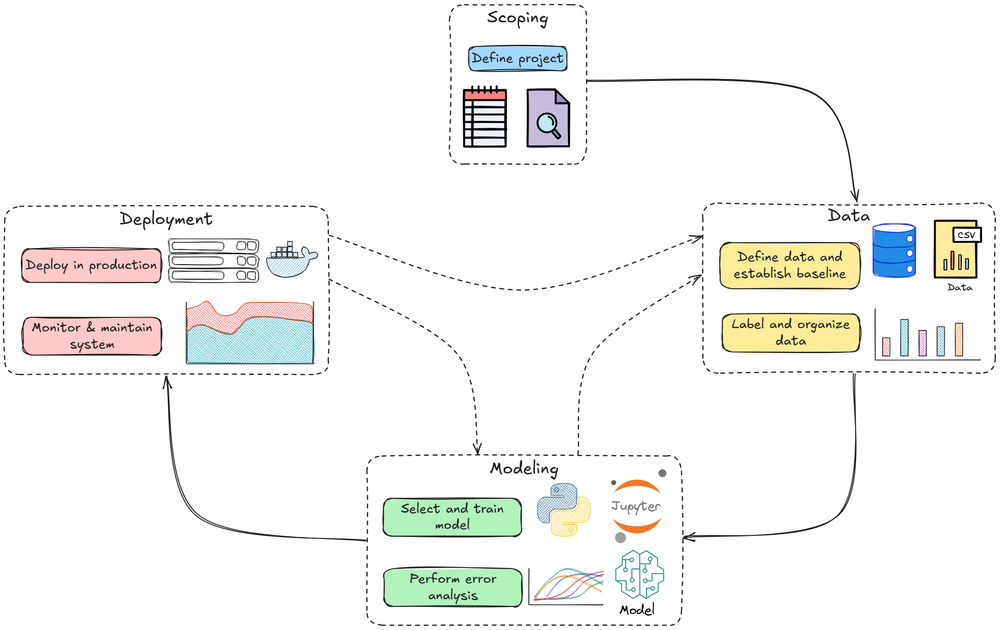
We’ll discuss:
- Data sources and formats
- ETL pipelines
- Practical Implementation
As always, every idea and notion will be backed by concrete examples, walkthroughs, and practical tips to help you master both the idea and the implementation.
Recap
In Part 3 of this MLOps and LLMOps crash course, we deepened our understanding of ML systems by exploring the importance of reproducibility and versioning.
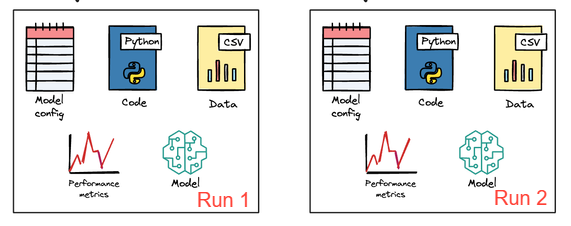
We began by exploring what reproducibility is, how versioning plays a key role in achieving it, and why these concepts matter in the first place.
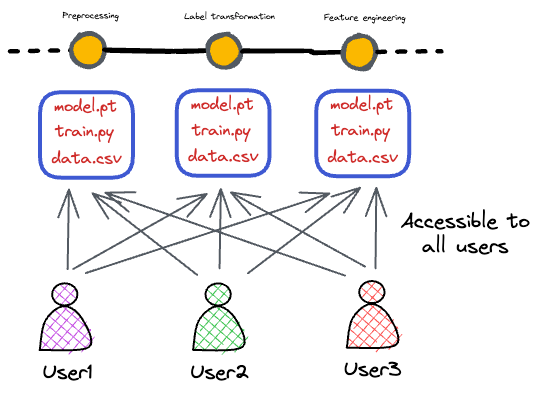
We examined the importance of reproducibility in areas such as error tracking, collaboration, regulatory compliance, and production environments.
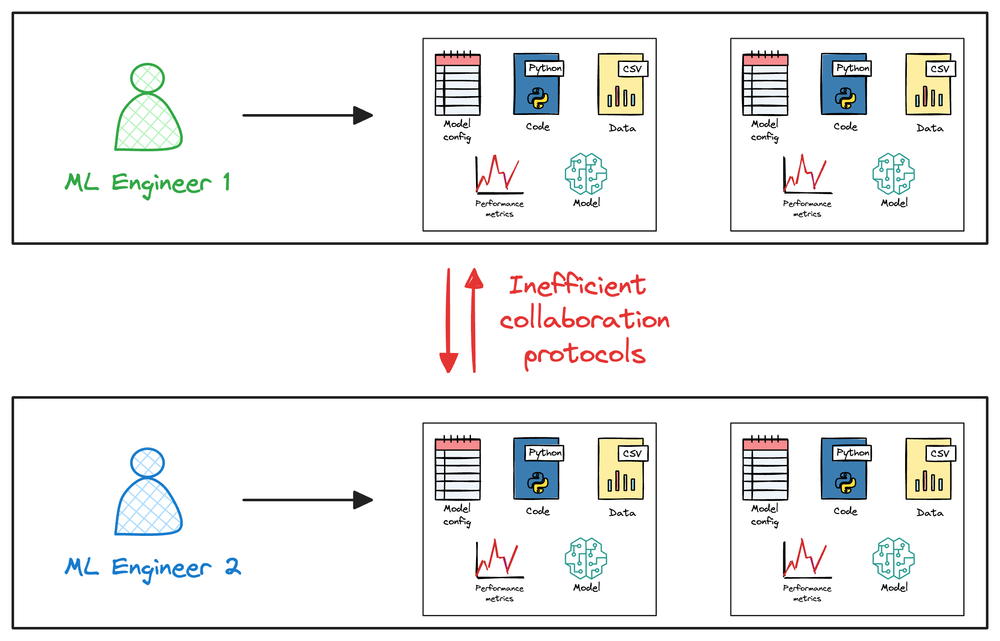
Collaboration issues due to lack of reproducibility
We then discussed some of the major challenges that can hinder reproducibility. We saw how ML being “part code, part data” adds the extra layers of complexity.
After that, we reviewed best practices to ensure reproducibility and versioning in ML projects and systems, including code and data versioning, maintaining process determinism, experiment tracking, and environment management.

Finally, we walked through hands-on simulations covering seed fixation, data versioning with DVC, and experiment tracking with MLflow.

If you haven’t explored Part 3 yet, we strongly recommend going through it first since it lays the conceptual scaffolding and implementational understanding that’ll help you better understand what we’re about to dive into here.
Recap
Before we dive into Part 3 of this MLOps and LLMOps crash course, let’s briefly recap what we covered in the previous part of this course.
In Part 2, we studied the ML system lifecycle in depth, breaking down the different stages into detailed explanations.
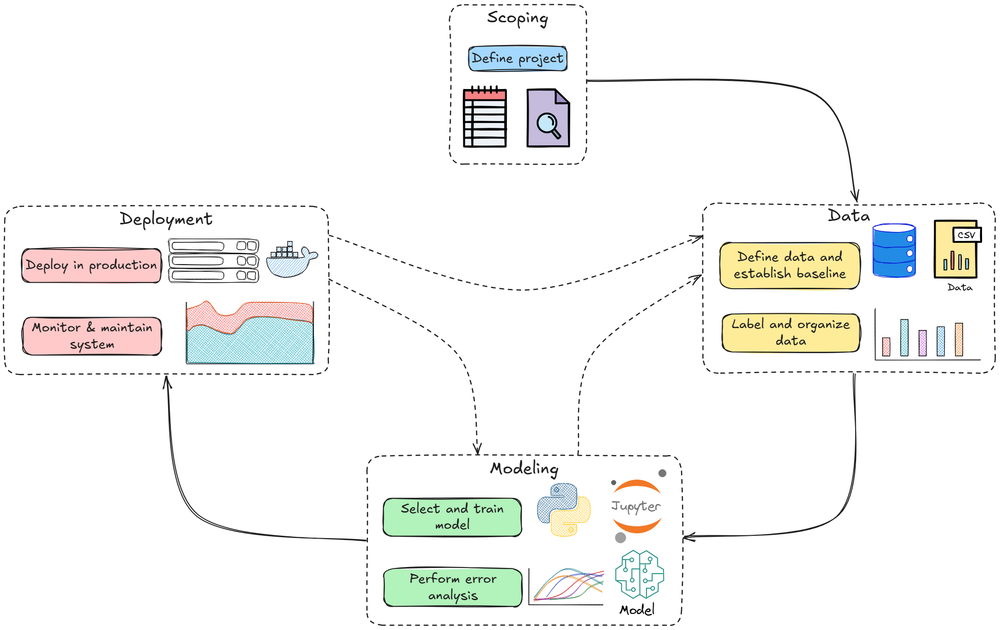
We started by understanding the first phase of the ML system lifecycle: data pipelines. It involved crucial concepts like ingestion, storage, ETL, labeling/annotation, and data versioning.
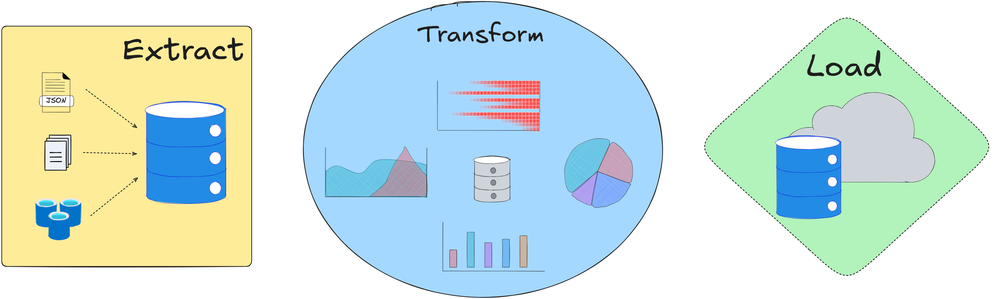
Next, we checked out the model training and experimentation phase, where we discussed crucial ideas related to experiment tracking, model selection, validation, training pipeline, resource management, and hyperparameter configuration.

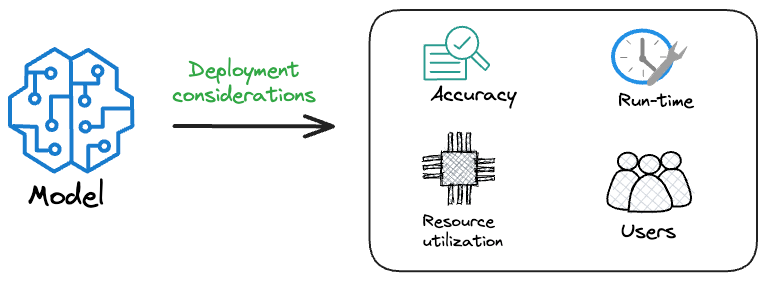
Moving further, we explored the deployment and inference stage. We went deep by understanding things like model packaging, inference, and deployment methodologies, testing, model registry, and CI/CD.
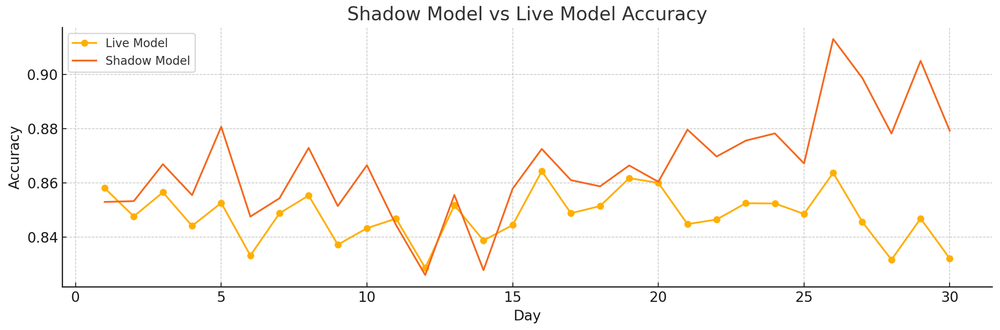
After deployment and inference, we went ahead and understood monitoring and observability. There, we checked out operational monitoring, drift, and performance monitoring.
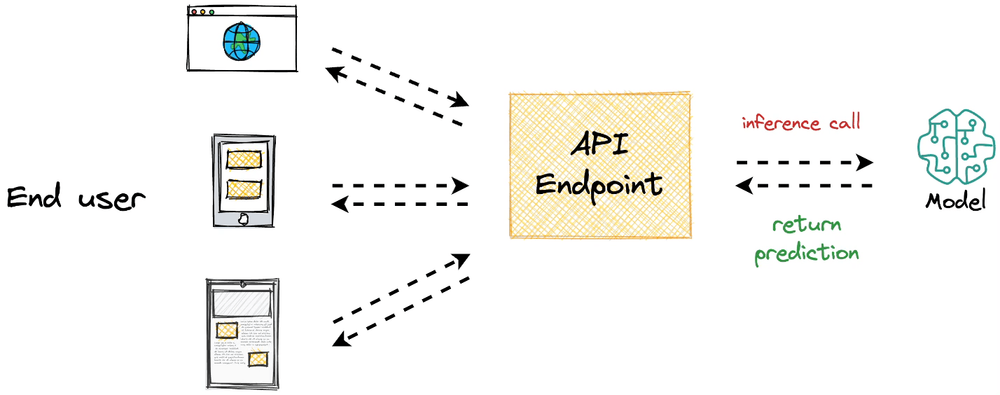
Finally, we walked through a quick hands-on simulation, where we studied how we serialize models, convert them into a FastAPI service, test them, and containerize for reproducibility and deployment
considerations.
If you haven’t yet studied Part 2, we strongly recommend reviewing it first, as it establishes the conceptual foundation essential for understanding the material we’re about to cover.
You can find it below:
In this chapter, we’ll explore reproducibility and versioning for ML systems, focusing on the key theoretical details and hands-on implementations, wherever needed.
As always, every notion will be explained through clear examples and walkthroughs to develop a clear understanding.