Bernstein says that it has become a strategic necessity if India wants to retain control over the next generation of technology and remain globally competitive.

India may lag in AI without its own foundation model
US restrictions show AI models are now strategic assets
Bernstein urges India to build domestic AI for tech autonomy
India needs to build its own foundational artificial intelligence (AI) model, or it may risk falling permanently behind the US and China with growing geopolitical restrictions on frontier AI models, according to a report by Bernstein.
The report argues that recent US restrictions on access to some of the latest AI models mark a turning point in the global AI race, signalling that cutting-edge large language models (LLMs) are increasingly being treated as strategic assets rather than commercially available software. If India continues to depend on foreign AI models while focusing only on application development, it risks ceding control over a critical layer of future technology, Bernstein said.
“India can’t build its AI future on borrowed models,” the brokerage said, adding that the country’s current strategy of building applications on top of foreign LLMs and investing in data centre infrastructure leaves it exposed to geopolitical risks.
Bernstein likened AI models to military assets, saying “AI is the next fighter jet”, as governments increasingly restrict access to advanced technologies ranging from semiconductor equipment and GPUs to frontier AI models. Foundational models, it argued, are no longer simply software products but strategic resources that countries may increasingly guard for national security and economic advantage.
The brokerage said the latest restrictions on access to Anthropic’s frontier models for non-US citizens demonstrate that access to advanced AI cannot be taken for granted. It warned that India could eventually find itself locked out of the most advanced AI systems or forced to operate using models that are one or two generations behind those available in the US and China. Such a scenario could leave Indian technology companies at a structural disadvantage, Bernstein said. Even companies with deep engineering talent could struggle to compete if they are building products using older AI models while startups elsewhere have access to cutting-edge systems.
India’s missing ‘DeepSeek’ moment
According to Bernstein, India has yet to produce its own “DeepSeek moment” because its technology ecosystem has historically been driven by IT services rather than consumer internet platforms that generate large proprietary datasets needed to train frontier AI models. The brokerage said India’s services-led technology model rewarded companies that customised and maintained software built by global firms, leaving little incentive to develop foundational AI capabilities. As a result, many policymakers and industry leaders have argued that India should focus on AI applications instead of building its own LLMs—a view Bernstein believes reflects the country’s historical trajectory rather than a deliberate long-term strategy.
AI sovereignty becoming a strategic necessary
Bernstein said AI is following the same path as technologies such as nuclear energy, defence systems and semiconductors, where access has historically been shaped by geopolitics rather than free markets.
It pointed to successive US export restrictions on advanced semiconductor equipment, GPUs and AI technologies, arguing that countries are increasingly treating AI as sovereign infrastructure. If similar controls continue to expand, India could find itself dependent on foreign governments for the intelligence layer powering enterprise software, defence, healthcare and financial systems.
Rather than relying solely on overseas AI models, India should build its own foundational capabilities while also developing specialised domain-specific LLMs using proprietary datasets in sectors such as healthcare, industrials and defence, Bernstein said.
Rethinking India’s AI policy
The brokerage also questioned whether India’s current AI strategy is sufficiently focused. While the IndiaAI Mission spans compute infrastructure, research, applications, hardware and foundational models, Bernstein argued that spreading limited resources across multiple priorities risks preventing the country from building meaningful leadership in any one area.
It suggested policymakers could either incentivise the development of domestic LLMs or require global AI companies to build India-based AI stacks insulated from geopolitical restrictions. Both approaches have trade-offs, Bernstein said, but they reflect the growing need to balance access to global AI with technological autonomy.
Ultimately, Bernstein argued that developing an indigenous foundational AI model is no longer optional.
“India’s own ‘DeepSeek’ has stopped being a luxury,” the brokerage said, adding that it has become a strategic necessity if the country wants to retain control over the next generation of technology and remain globally competitive.
DeepSeek is a prominent Chinese artificial intelligence company based in Hangzhou that develops highly advanced, open-weight large language models (LLMs). Founded in July 2023 by Liang Wenfeng and funded by the quantitative hedge fund High-Flyer, the company has disrupted the global AI industry by delivering frontier-level AI performance at a fraction of the cost of its Western competitors.
Key Core Models
- DeepSeek-V4: The flagship model family available in “Pro” (1.6 trillion total parameters) and “Flash” versions. It features a massive 1-million token context window and groundbreaking architectural designs like Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to cut memory overhead by up to 90%.
- DeepSeek-R1: A specialized reasoning model released in early 2025 that uses intensive Reinforcement Learning (RL). It exhibits emergent capabilities such as self-reflection, complex mathematics solving, and advanced coding.
General reasoning represents a long-standing and formidable challenge in artificial intelligence. Recent breakthroughs, exemplified by large language models (LLMs) and chain-of-thought prompting, have achieved considerable success on foundational reasoning tasks. However, this success is heavily contingent upon extensive human-annotated demonstrations, and models’ capabilities are still insufficient for more complex problems. Here we show that the reasoning abilities of LLMs can be incentivized through pure reinforcement learning (RL), obviating the need for human-labeled reasoning trajectories. The proposed RL framework facilitates the emergent development of advanced reasoning patterns, such as self-reflection, verification, and dynamic strategy adaptation. Consequently, the trained model achieves superior performance on verifiable tasks such as mathematics, coding competitions, and STEM fields, surpassing its counterparts trained via conventional supervised learning on human demonstrations. Moreover, the emergent reasoning patterns exhibited by these large-scale models can be systematically harnessed to guide and enhance the reasoning capabilities of smaller models.
DeepSeek-V3: A powerful Mixture-of-Experts (MoE) base model trained on 14.8 trillion tokens using highly efficient FP8 training frameworks. We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks.
Why It Disrupted the AI Industry
Extreme Cost Efficiency: DeepSeek’s models are notoriously inexpensive to host and query. DeepSeek Climbs US Corporate Expense Reports as Companies Chase Cheaper AI According to new data from Ramp, the corporate spend management platform, DeepSeek has become the top trending software vendor among US businesses in June 2026.

The ranking, which tracks first-time purchases across tens of thousands of companies, shows that more American firms are now directly paying for DeepSeek’s API — a clear signal that cheaper alternatives to OpenAI and Anthropic are moving from experiments into real budgets.
When Token Price Stops Being Theoretical
As AI shifts from pilot projects to daily operational use, the cost per token has stopped being a minor technical detail and become a line item that finance teams actually care about.

This is especially true for agentic workflows, where a single user request can trigger dozens of model calls — tool use, web searches, code execution, document analysis, retries, and growing context windows. In these scenarios, even modest price differences per token can translate into massive differences in monthly bills.
OpenAI and Anthropic still dominate in brand strength, ecosystem integration, compliance features, and reliability. However, companies are increasingly asking a simple question: Is the premium worth it when a capable alternative costs significantly less?
Pragmatism Over Politics
The most interesting part of this trend is how little ideology seems to be influencing decisions.
Despite ongoing geopolitical tensions around Chinese AI models, many companies appear to be making pragmatic choices based on three factors:
- Model quality is “good enough” for their use case;
- The API is reliable and easy to integrate;
- The bill at the end of the month is noticeably lower.
Ramp’s data shows that DeepSeek isn’t just being used through third-party platforms — US companies are routing data directly to DeepSeek’s service. This suggests real production usage rather than just developer experimentation.
The New Economics of AI Adoption
The rise of cost-sensitive players like DeepSeek, alongside other inference providers (Fireworks AI, DeepInfra, etc.), is forcing a recalibration of AI economics. Organizations are moving from “Can we afford to use AI?” to “Which model gives us the best cost-performance ratio at scale?”
 For many agent-heavy applications — customer support automation, research agents, internal tools, and workflow automation — the difference in per-token pricing can determine whether a project is economically viable or not.
For many agent-heavy applications — customer support automation, research agents, internal tools, and workflow automation — the difference in per-token pricing can determine whether a project is economically viable or not.
This doesn’t mean OpenAI and Anthropic are losing their position. Their advantages in safety, ecosystem, and enterprise features remain significant for many use cases. But the market is clearly becoming more price-sensitive as AI moves deeper into operations.
Major Tech Integrations: Due to its lower cost, tech giants like Microsoft are exploring Azure integration for fine-tuned versions of DeepSeek V4 within their Copilot framework. Microsoft exploring use of DeepSeek V4 as Anthropic and Claude models are too expensive Xiaomi announces new AI coding agent that actually remembers what it was doing the past decade, Xiaomi has evolved from a smartphone manufacturer to an EV maker to a global technology leader, offering a wide range of smart devices and innovative solutions. Known for its commitment to quality, affordability, and cutting-edge technology, Xiaomi continues to push the boundaries of what’s possible in consumer electronics at an affordable price.
Smartphones: From Flagship to Budget
Xiaomi’s smartphone lineup caters to every user and budget:
- Xiaomi Series: Flagship devices featuring the latest technology, including the anticipated Xiaomi 15 series.
- Redmi Series: Budget-friendly smartphones that don’t compromise on features.
- POCO Series: Performance-focused devices that offer high-end specs at competitive prices.
Smart Home Ecosystem
Xiaomi’s vision extends beyond smartphones, encompassing a comprehensive smart home solution:
- Smart TVs and streaming devices
- Home security cameras and sensors
- Air purifiers and smart lighting
- Robot vacuums and other household appliances
Wearables and Personal Electronics
Enhancing personal technology with:
- Xiaomi Watch series
- Fitness bands and trackers
- True wireless earbuds
- Power banks and charging solutions
Xiaomi’s Commitment to Innovation
5G Leadership: Pioneering affordable 5G devices to make next-gen connectivity accessible to all.
MIUI: Xiaomi’s custom Android skin, constantly evolving with new features and optimizations.
AI Integration: Incorporating artificial intelligence across devices for smarter, more intuitive experiences. We’ve been covering Xiaomi’s MiMo journey from the very beginning. The MiMo-7B is the company’s first open-source reasoning and coding model, announced back in 2025. MiMo Code builds on that same foundation, but instead of being just a model, it’s a complete coding agent designed to help with long-running software projects directly from the terminal. The tool is based on the open-source OpenCode project and is released under the MIT license, meaning developers are free to use, modify, and build on it. Out of the box, it includes free access to MiMo-V2.5, Xiaomi’s latest multimodal AI model, but users can also connect it to third-party services such as DeepSeek, Kimi, and GLM if they prefer a different backend.
Tackling AI’s memory problem
One of MiMo Code’s highlight features is its persistent memory system. Most AI coding assistants depend entirely on the model’s context window, and once that fills up, they start forgetting earlier decisions or conversations.
Meanwhile, MiMo code has a dedicated background subagent that continuously manages and stores context while you work. When the active conversation gets close to its limit, the subagent automatically condenses everything into a structured summary, allowing the main agent to continue without losing its place.
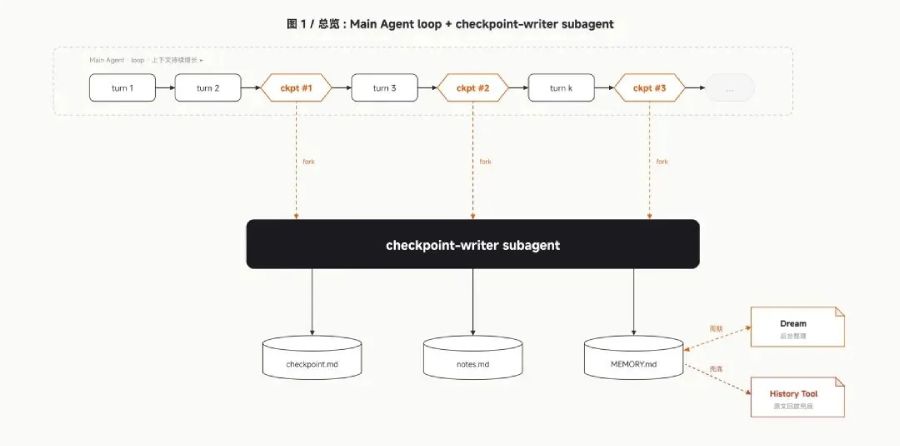
Xiaomi has also included a feature called /dream, which runs automatically every seven days. This launches a separate maintenance agent that reviews old sessions and memory files, removes duplicates, verifies file paths, and compresses everything into an updated long-term memory store.
Compose mode and the MiMo Harness
MiMo Code also introduces a dedicated Harness system built specifically for MiMo models. Rather than treating the AI as a generic API endpoint, the framework is designed to take advantage of the model’s underlying capabilities more directly.
That works alongside a feature called Compose mode, activated by pressing the Tab key. Instead of asking the AI to complete one step at a time, you can provide a rough idea or goal, and the agent will attempt to handle the entire workflow—from planning and design to coding, testing, and review. Xiaomi says this approach can produce what it describes as an “industrial-grade finished product.” That’s a bold claim, but the company points to benchmark results to back it up. According to Xiaomi, MiMo Code achieved scores of 62% on SWE-Bench Pro and 73% on Terminal Bench 2, outperforming Claude Code by around five percentage points while using the same underlying base model.
The assistant also comes with built-in voice input powered by MiMo-V2.5-ASR. Users can dictate commands, fix typos, or trigger actions such as “send” and “execute” without touching the keyboard.
Getting started
You can set up MiMo Code very simply. On macOS and Linux, installation requires a single terminal command, while Windows users can install it through npm. Once it’s installed, launching the tool is as simple as typing mimo in the terminal.
The initial setup automatically guides users through model configuration, and Xiaomi says the free MiMo-V2.5 channel can be used without creating an account or going through a registration process. But all that smart chaining of tasks comes with a catch: it burns through a ton of computing power, and the bills can add up fast.

According to reports, Microsoft has made Copilot Cowork generally available to Microsoft 365 Copilot customers and shifted it to usage-based pricing. Instead of a straight flat fee that didn’t always match heavy usage, companies will now pay based on actual “Copilot Credits”, basically metering the real computational load for each task. On top of the pricing shift, Microsoft is looking at ways to bring costs down even further. They’re exploring a fine-tuned, self-hosted version of DeepSeek V4 (or another open-source model) as a more affordable option alongside the current Anthropic and OpenAI models. DeepSeek V4 has been delivering strong performance at much lower prices, sometimes a fraction of what frontier models cost per token.
Importantly, any DeepSeek integration would be optional and run entirely on Azure. That means customer data stays inside Microsoft’s secure cloud environment with all the usual enterprise-grade protections, compliance, and data residency controls. It’s a smart way to address potential concerns about using a Chinese-developed model in sensitive business settings.

This whole move shows how the AI industry is maturing. Agentic AI is incredibly useful because it can keep working through long chains of tasks and maintain context, but that same power makes it expensive to run at scale. By offering model choices and metered billing, Microsoft is trying to strike a better balance so more businesses can actually adopt these tools without sticker shock. It’ll be interesting to see in the coming weeks which lower-cost model they land on and how customers respond. Overall, this feels like a practical step toward making advanced AI agents part of normal work life instead of just a high-end experiment. Cost efficiency and flexibility could be the real keys to widespread adoption.
Open-Source Distillation: DeepSeek openly shares its model weights, allowing researchers to distill its complex reasoning workflows into much smaller, accessible models (ranging from 1.5B to 70B parameters). We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning. With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
Post-Training: Large-Scale Reinforcement Learning on the Base Model
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model’s reasoning and non-reasoning capabilities. We believe the pipeline will benefit the industry by creating better models.
Distillation: Smaller Models Can Be Powerful Too
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|---|
| Architecture | – | – | MoE | – | – | MoE | |
| # Activated Params | – | – | 37B | – | – | 37B | |
| # Total Params | – | – | 671B | – | – | 671B | |
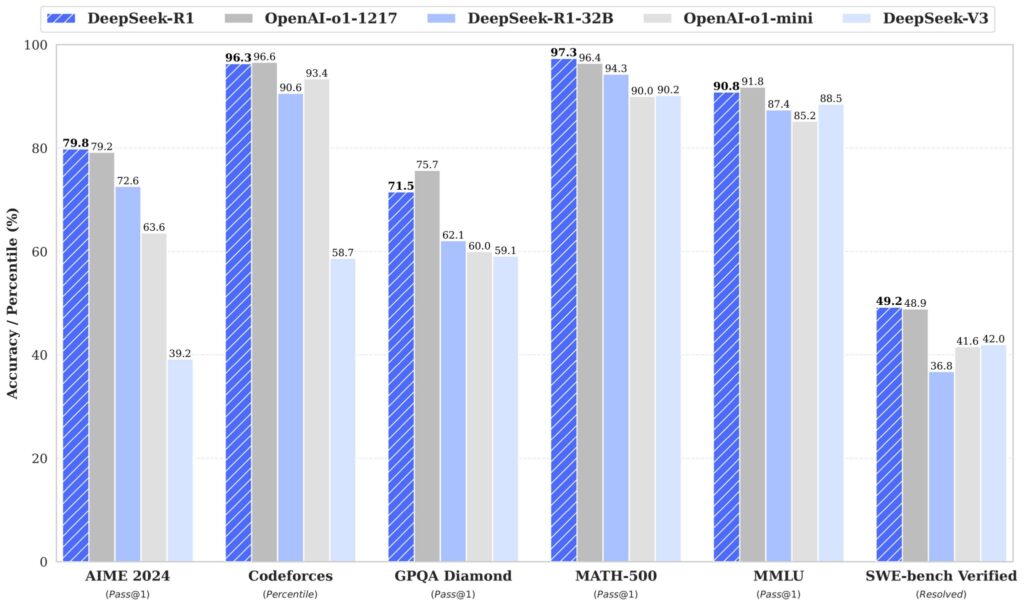
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | – | 92.9 | |
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | – | 84.0 | |
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | – | 83.3 | |
| GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 | |
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 | |
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | – | 82.5 | |
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | – | 87.6 | |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | – | 92.3 | |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | – | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 | |
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 | |
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 | |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | – | 78.8 | |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | – | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | – | 91.8 | |
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | – | 63.7 |
Distilled Model Evaluation
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:
- Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
- Avoid adding a system prompt; all instructions should be contained within the user prompt.
- For mathematical problems, it is advisable to include a directive in your prompt such as: “Please reason step by step, and put your final answer within boxed{}.”
- When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting “<think>nn</think>”) when responding to certain queries, which can adversely affect the model’s performance. To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with “<think>n” at the beginning of every output.
7. License
This code repository and the model weights are licensed. DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs.
Please note that:
Access & Services
You can interact with their ecosystem through several different official avenues:
Mobile App: Accessible on mobile platforms via the DeepSeek Google Play App.
Models & Pricing
The prices listed below are in units of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the total number of input and output tokens by the model.
(1) The model names deepseek-chat and deepseek-reasoner will be deprecated on 2026/07/24 15:59 UTC. For compatibility, they correspond to the non-thinking mode and thinking mode of deepseek-v4-flash, respectively.
Deduction Rules
The expense = number of tokens × price. The corresponding fees will be directly deducted from your topped-up balance or granted balance, with a preference for using the granted balance first when both balances are available.
Product prices may vary and DeepSeek reserves the right to adjust them. We recommend topping up based on your actual usage and regularly checking this page for the most recent pricing information.